这是前阵我所负责的一个服务线上偶发性的问题,就是在早高峰请求量大的时候,线上机器偶尔会有一两台夯住,重启就会恢复。现将我之前总结的排查解决过程记录在自己的博客(benxiaopao.com)里分享。
一、简要概述
问题原因是出现竞态资源,异步中嵌套异步,导致线程资源占满等待。有一点类似同步中嵌套同步,可能导致锁无法释放容易出现死锁。简化图示如下:
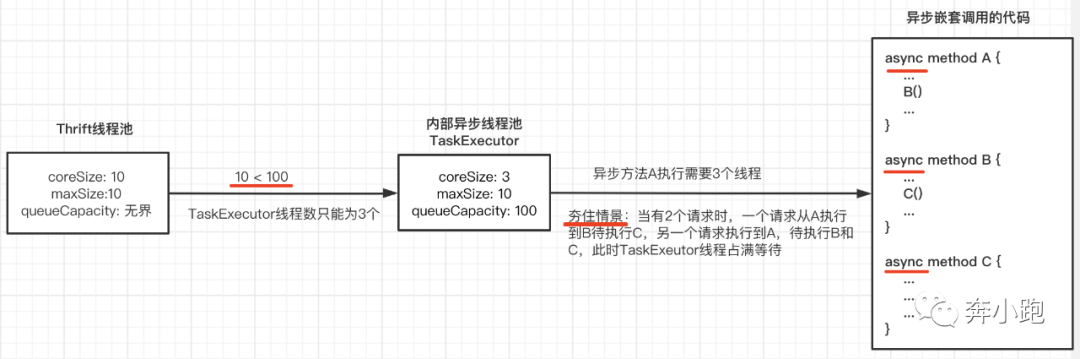
出现的竞态资源就是TaskExecutor中的线程资源。上面的例子是简化的:Thrift线程池线程数为10个,小于内部异步线程池TaskExecutor中的队列大小100,所以TaskExecutor在程序运行期间线程数据只能为3个,而异步嵌套的方法A执行需要3个线程,当有2个请求时,可能的情景是一个请求从A执行到B,待执行C,另一个请求执行到A,待执行B和C,此时TaskExecutor中的3个线程就被占用完了,如果要继续执行完,需要再获取新的线程资源,但又没有可用的线程资源可用,所以程序会一直夯在这里。
二、具体分析总结
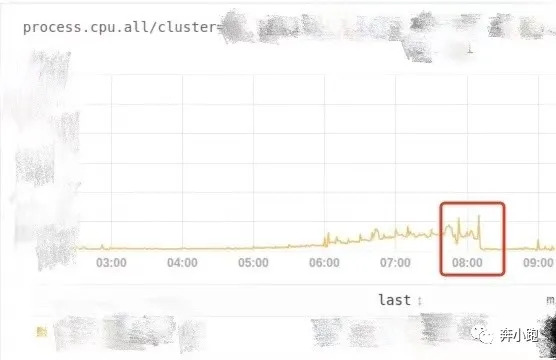
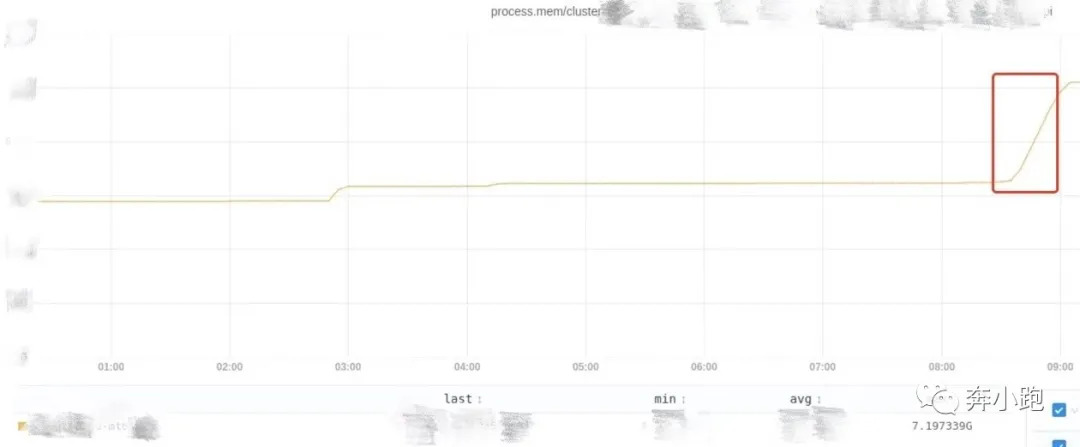
问题现象表现为每天早高峰时,会在8:15左右时常爆出有时延问题,通过查看监控会发现有1 ~ 2台机器hang住,程序端口还在,但没有服务能力了,通过重启可以暂时恢复hang住机器的服务。查看项目日志没有明显error,gc日志也没有出现full gc。监控查看8:15左右的cpu和内存使用情况,均无特别明显异常,但发现在机器夯住以后,如果未及时重启机器,对应机器的内存会一直飙升,说明thrift请求还能打进来,只是没有服务处理能力了(CPU和内存监控截图如下)。
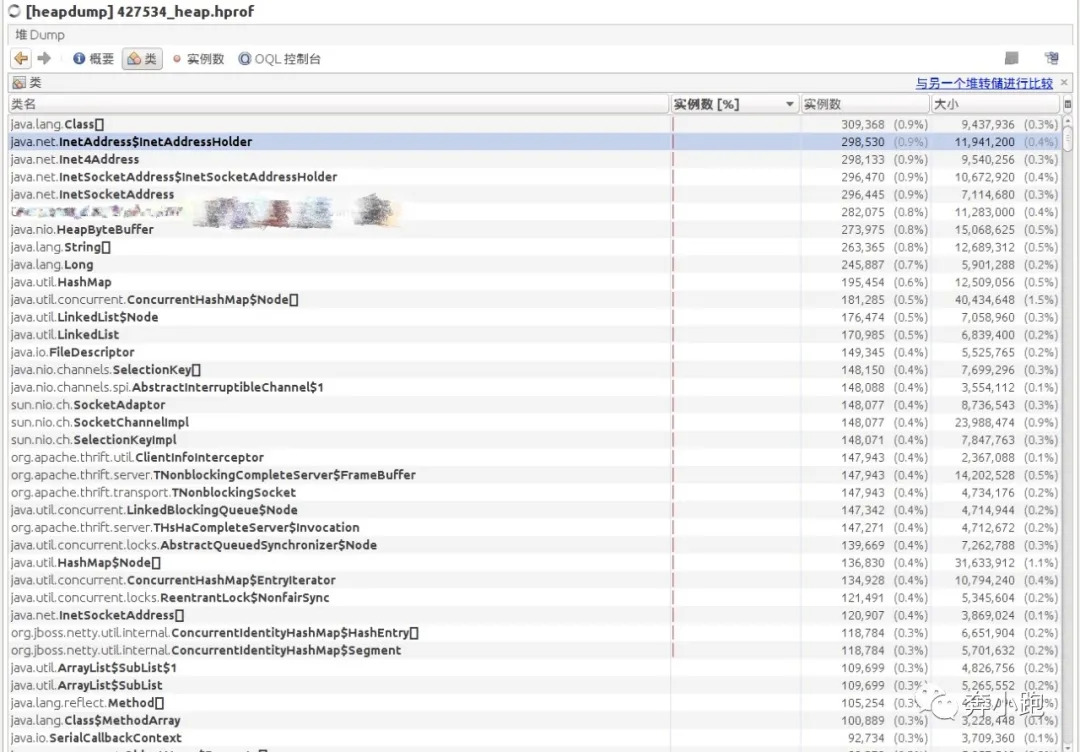
后面通过dump的几次现场文件分析,发现网络类对应的实例对象较多(截图如下),说明thrift请求数据有堆积,通过查看相关代码知道thrift的线程池使用的是无界队列。
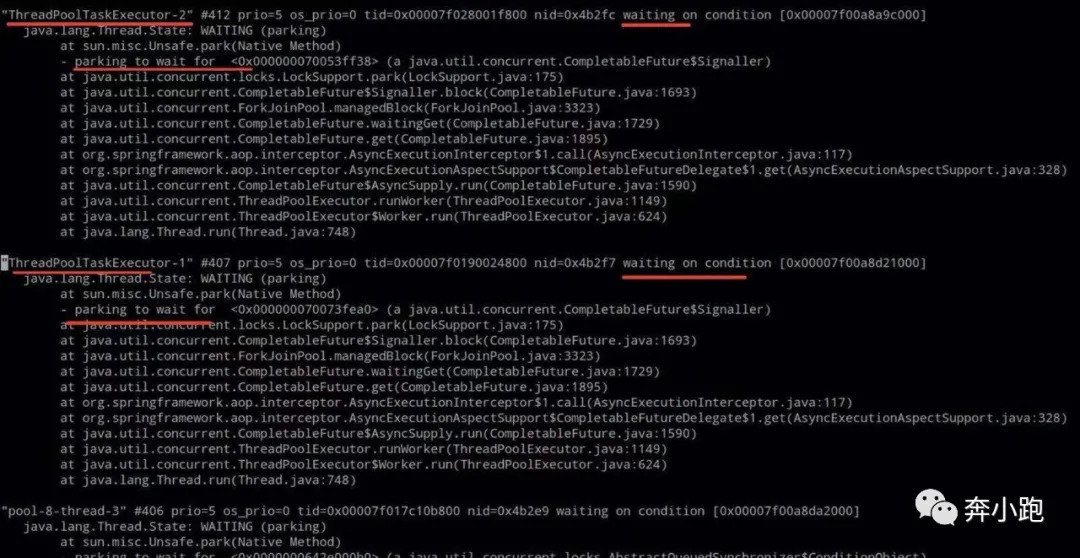
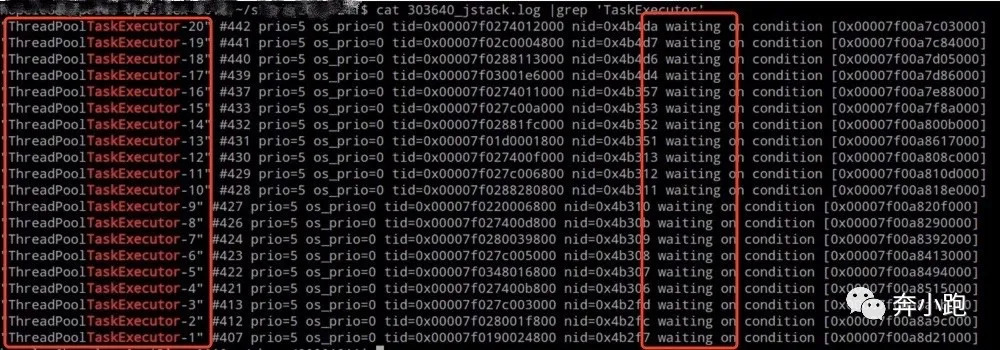
通过jstack文件发现大多数线程处于waiting状态,发现ThreadPoolTaskExecutor-字样的线程只有20个,全部处于waiting状态(截图如下),这对应了项目中的@Async对应的线程池配置。
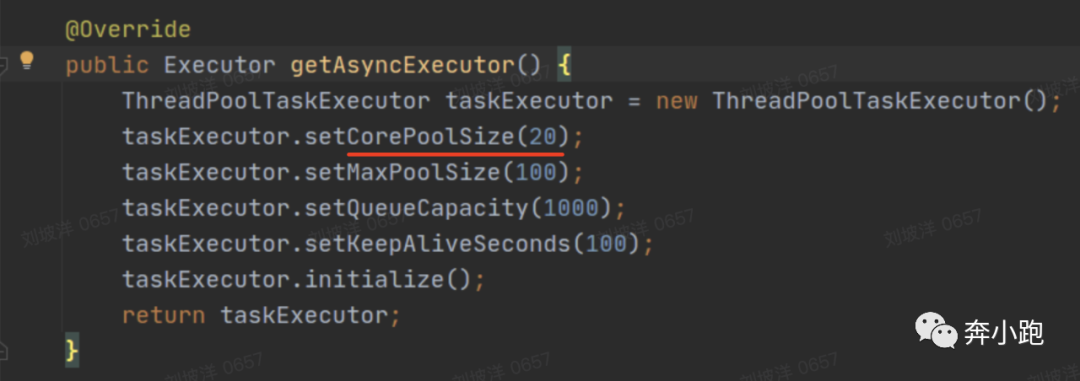
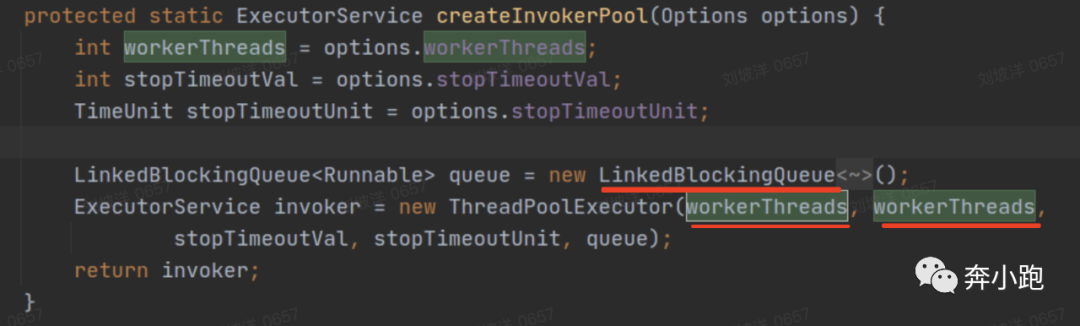
最终分析该问题的根本原因是线程资源占用完一直waiting导致,涉及上面提到的两个主要线程池,一个是thrift线程池,一个是项目内部执行异步任务的线程池TaskExecutor。Thrift线程池定义了100个线程。查看使用的thrift jar包知道核心线程数和最大线程数都是使用的自定义的数目100,队列是无界的LinkedBlockingQueue队列。该线上服务项目中使用了spring的@Async方式实现异步调用逻辑,其定义的线程池情况是核心线程数20,最大线程数100,队列容量1000。接口服务中有的请求存在异步的方法调用异步方法的逻辑,例如:异步的A方法调用了异步的B方法和异步的C方法,A方法会从TaskExecutor线程池中拿一个线程执行,其调用B方法时,也会从TaskExecutor线程池中拿一个线程运行,同样调用C方法时也会拿一个线程运行,此时该请求会占用TaskExecutor线程池中3个线程,当并发不高或执行耗时很短情况下,线程很快会释放,但如果并发量很大或异步方法中的子操作耗时较长时,会出现一种状况,TaskExecutor线程池中的20个核心线程被占用完,此时再来请求的话,异步任务会进入TaskExecutor线程池中的1000容量的队列当中等待,又由于请求入口是thrift接口,而thrift线程总共就100个,所以异步的任务不会达到1000个,不会把TaskExecutor线程池中的队列用完,也就不会再创建新的线程,因此TaskExecutor的线程数只能是20个,而这20个线程在高并发的情况下已经被占用,并且他们要执行完,还需要子操作再从TaskExecutor线程池中拿空闲线程,所以只能一直waiting,导致服务程序hang住,报出时延问题。该问题一般不会太频繁出现,但在并发量高的情况下通常会较常暴露出现。
三、解决处理及启发
去掉异步方法的嵌套调用即可解决该问题,也可以按实际需要,如果服务接口逻辑中没太多并行处理的业务逻辑,也可以把@Async的线程池去掉。
带来的启发有:
- 排查该类问题,理论上可以以三个方向Full GC、长时间运行的服务内存泄露、线程死锁为线索,因为这三类问题会使系统响应能力急剧下降或停止服务,未解决前只得重启。
- 使用线程时,结合项目实际情况,定义合适的线程大小。
- 使用多线程编程时,注意竞态资源的使用情况,尽量避免文中描述的异步方法嵌套调用异步方法,使用同步锁方法嵌套调用同步锁方法。
- 也可以增加必要的限流限时控制,超过设置的条件时可以kill掉请求及时释放掉占用的资源。