一 Michelangelo概述
- Michelangelo 机器学习平台是一个内部的“MLaaS”(机器学习即服务)平台。
- 不仅支持传统的机器学习模型,还支持时间序列预测以及深度学习。
- 可以让公司内部团队无缝构建、部署与运行 Uber 规模的机器学习解决方案。
- 用以降低机器学习开发的门槛,根据商业需求对 AI 进行拓展与缩放。
应用举例:UberEATS 送餐到家时间预估模型
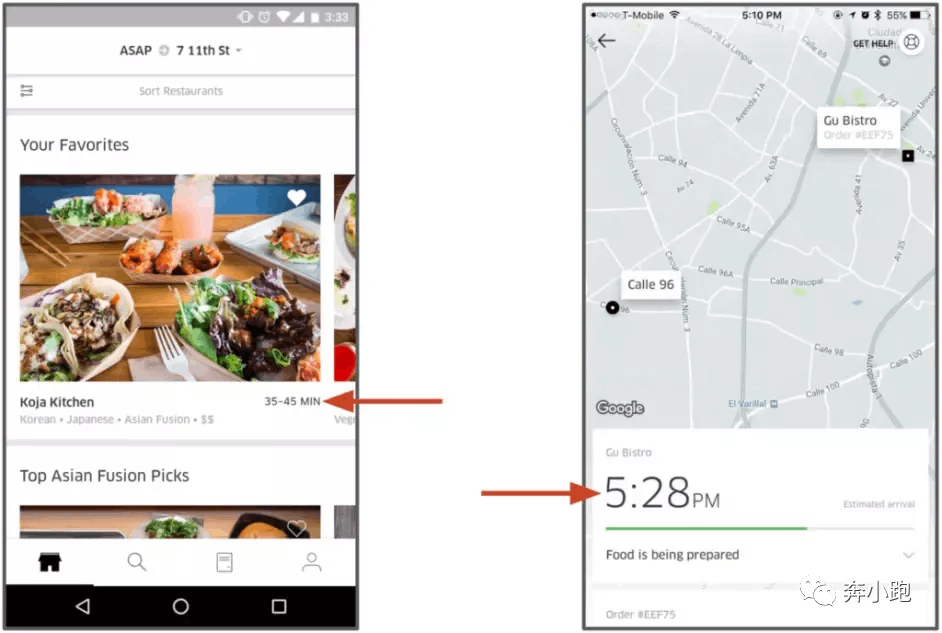
备注:UberEATS app 提供了估测外卖送达时间的功能,此功能由基于米开朗基罗构建的机器学习模型驱动
- 使用了 GBDT(梯度提升决策树)回归模型来预测这种端到端的送达时间。
- 此模型使用的特征包括请求信息(例如时间、送餐地点)、历史特征(例如餐厅在过去 7 天中的平均餐食准备时间)、以及近似实时特征(例如最近一小时的平均餐食准备时间)。
- 部署于 Uber 数据中心的米开朗基罗平台提供的容器中,通过 UberEATS 微服务提供网络调用。
- 预测结果将在餐食准备及送达前展示给客户。
二 Michelangelo系统架构
Michelangelo 由一些开源系统和内置组件组成,主要开源组件有 HDFS、Spark、Samza、Cassandra、MLLib、XGBoost、TensorFlow。
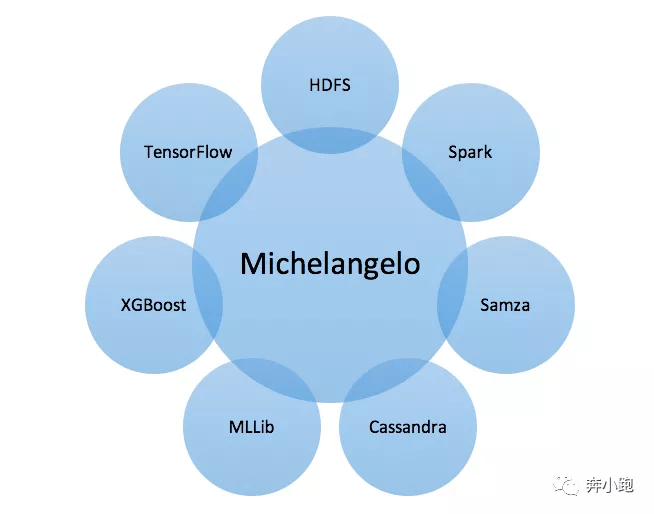
这些开源工具各司其职,HDFS存储着Uber所有的事务和记录数据,Kafka用来汇集Uber各项服务的日志信息,Samza(注: 平台已把逻辑迁移到 Flink)用来进行流计算并且从中计算一些实时features,Cassandra是用来提供实时数据访问的工具。
“数据湖”,包含了 Uber 所有的事务和日志数据。由 Kafka 对 Uber 的所有服务日志进行采集汇总,使用 Cassandra 集群管理的 Samza (注: 平台已把逻辑迁移到 Flink)流计算引擎以及 Uber 内部服务进行计算与部署。
三 Michelangelo工作流程
Michelangelo 专门设计提供可拓展、可靠、可重用、易用的自动化工具,主要负责实现典型机器学习工作流程中的以下六个阶段

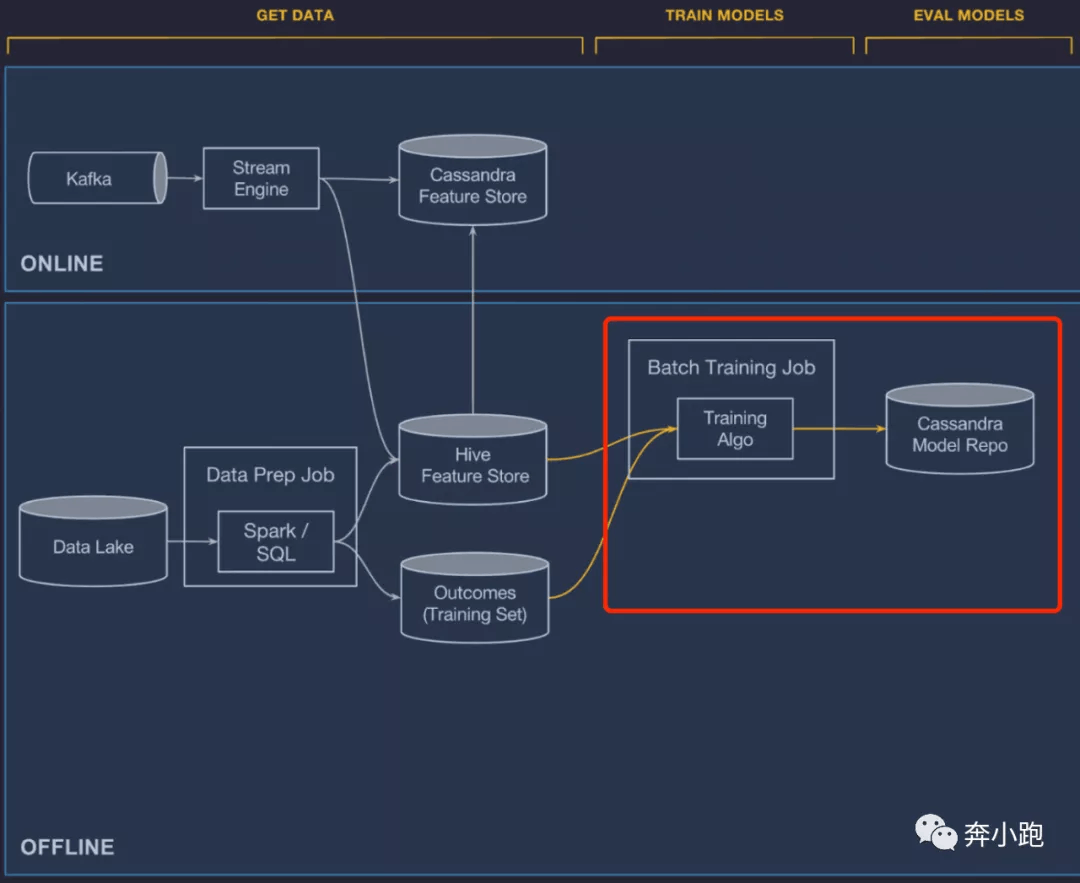
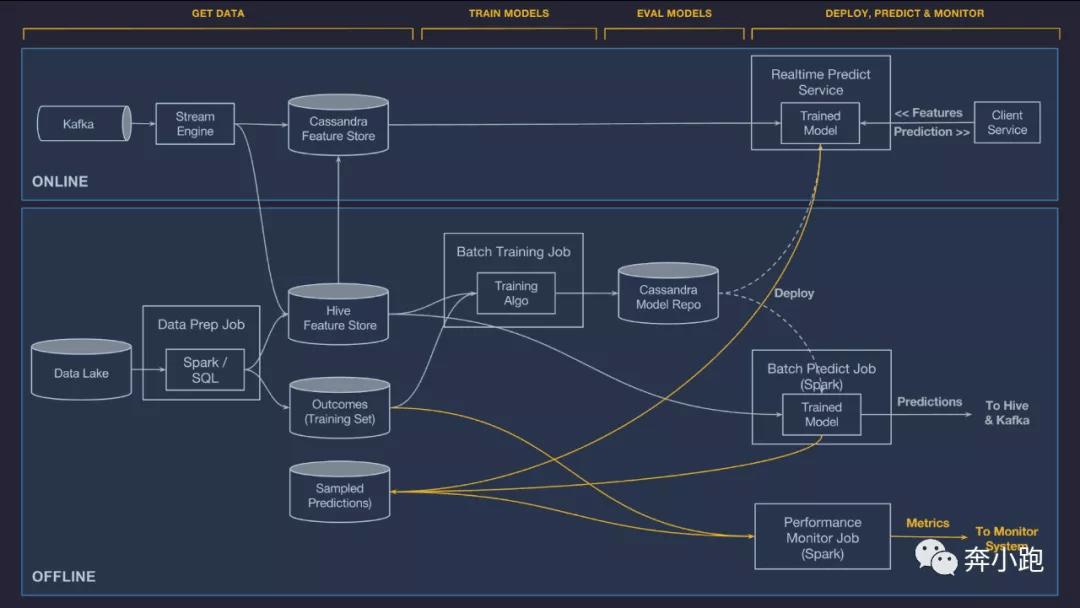
3.1 管理数据
数据管理组件分为
- 在线管道。 为在线、低时延预测作业提供数据
- 离线管道。 用于为批量模型训练以及批量预测作业提供数据
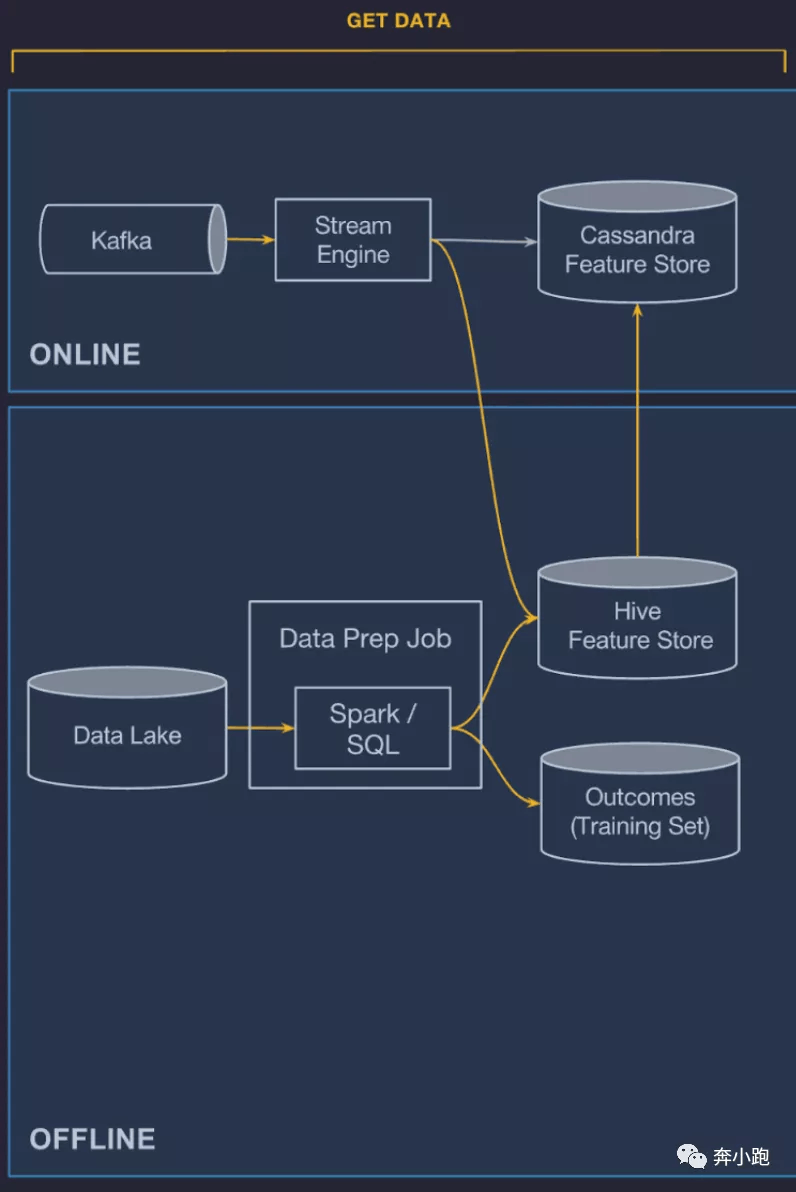
数据流转说明:
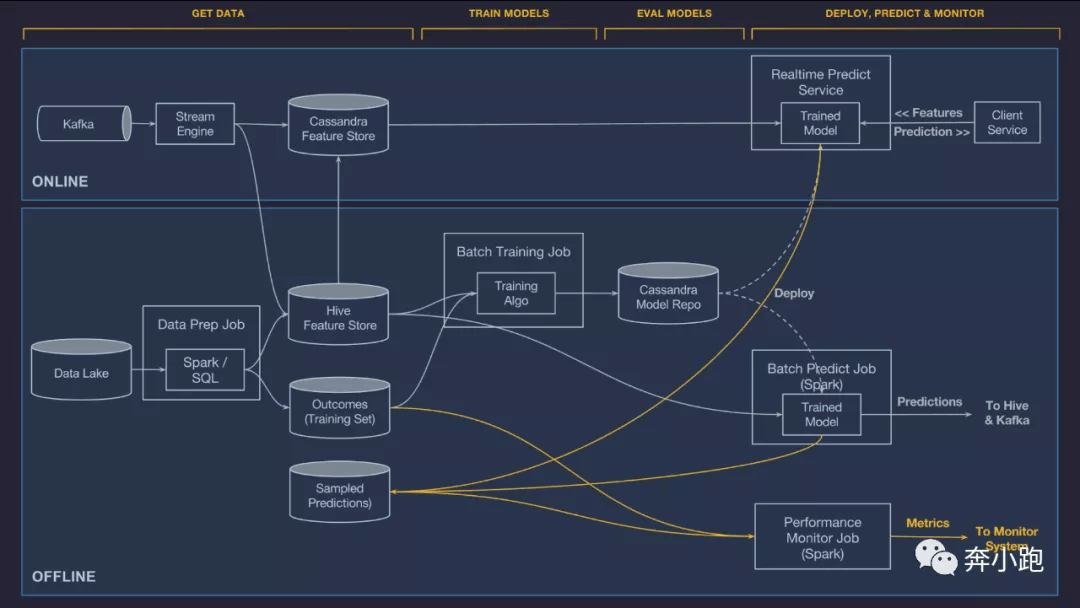
特征生成管道(Stream Engine 和 Data Prep Job)经工作流引擎的调度,从 Kafka 流数据源 和 Data Lake 批数据源读取数据,转换成供 ML 模型使用的特征,写入特征仓库(Cassandra Feature Store 和 Hive Feature Store)。一旦特征落库,就可以供在线预测(Realtime Predict Service)、离线训练(Batch Training Job)和离线预测(Batch Predict Job)使用。
特征存储系统价值作用:可以让各个团队共享类似或相同的特征、发现高质量的数据特征以解决他们的机器学习问题。
3.2 训练模型
训练模型可以看成是一种寻找最佳特征、算法、超参以针对问题建立最佳模型的探索过程。
- 平台支持离线、大规模分布式训练,包括决策树、线性模型、逻辑模型、无监督模型(k-means)、时间序列模型以及深度神经网络。
- 用户也可以自己提供模型类型,包括自定义训练、评价以及提供服务的代码。
在模型训练完毕之后,系统会将其计算得到的性能指标(例如 ROC 曲线和 PR 曲线)进行组合,得到一个模型评价报告。在训练结束时,系统会将原始配置、学习到的参数以及评价包括存回模型库,用于分析与部署。
3.3 评估模型
追踪训练过的模型(例如谁、何时训练了它们,用了什么数据集、什么超参等),对它们的性能进行评估、互相对比,可以为平台带来更多的价值与机会。
Michelangelo 中训练的每个模型都需要将以下信息作为版本对象存储在 Cassandra 的模型库中:
- 谁训练的模型。
- 训练模型的开始时间与结束时间。
- 模型的全部配置(包括用了什么特征、超参的设置等)。
- 引用训练集和测试集。
- 描述每个特征的重要性。
- 模型准确性评价方法。
- 模型每个类型的标准评价表或图(例如 ROC 曲线图、PR 曲线图,以及二分类的混淆矩阵等)。
- 模型所有学习到的参数。
- 模型可视化摘要统计。
模型库中的这些数据可以通过 Web UI 或者使用 API 获取,用以生成报告和可视化展示(以下三个示例)。
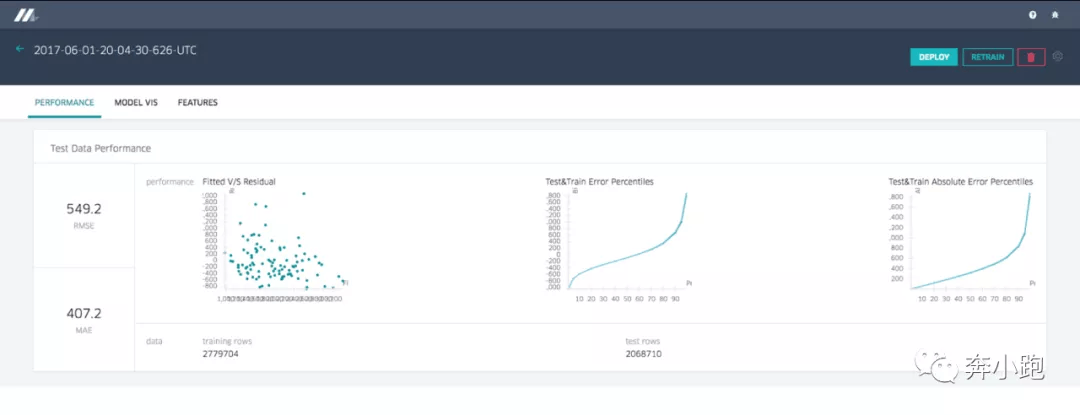
3.3.1 模型准确率报告
举例:回归模型的准确率报告,展示了标准的准确率指标与图表
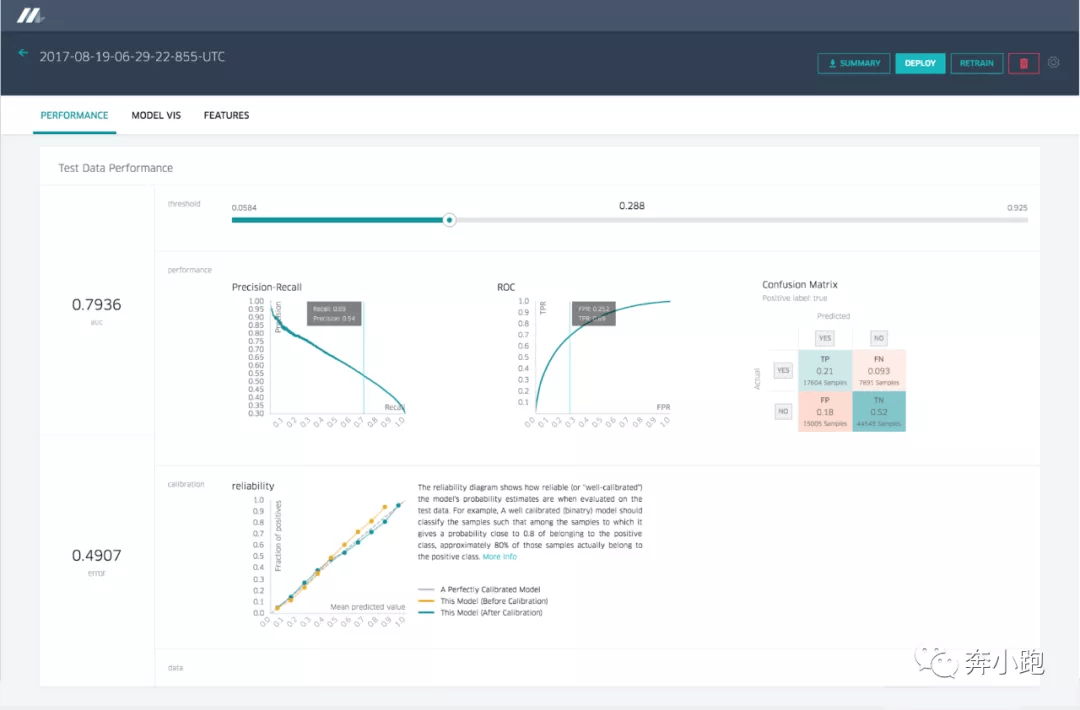
举例:分类模型的准确率报告,展示了不同的分类集合
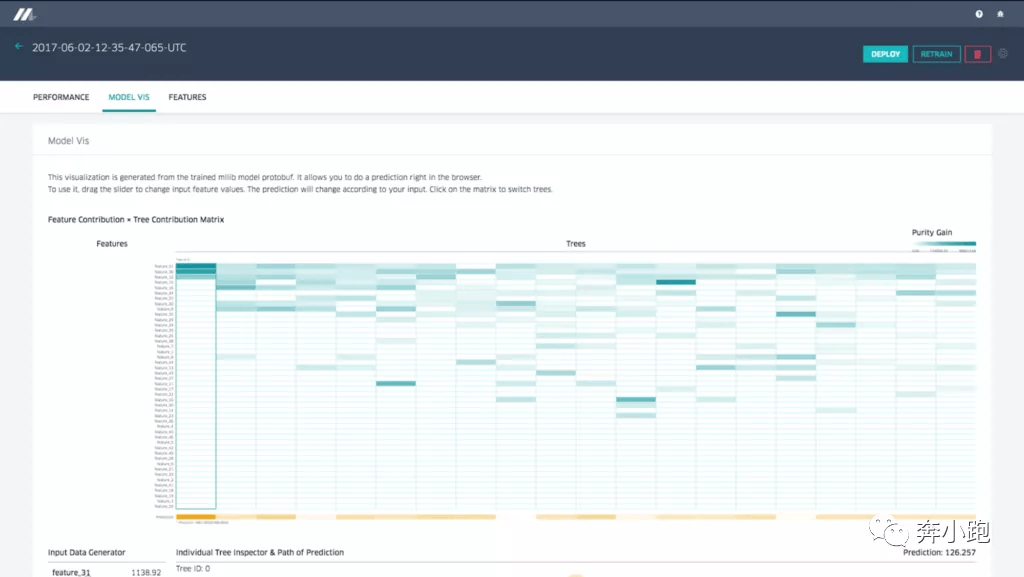
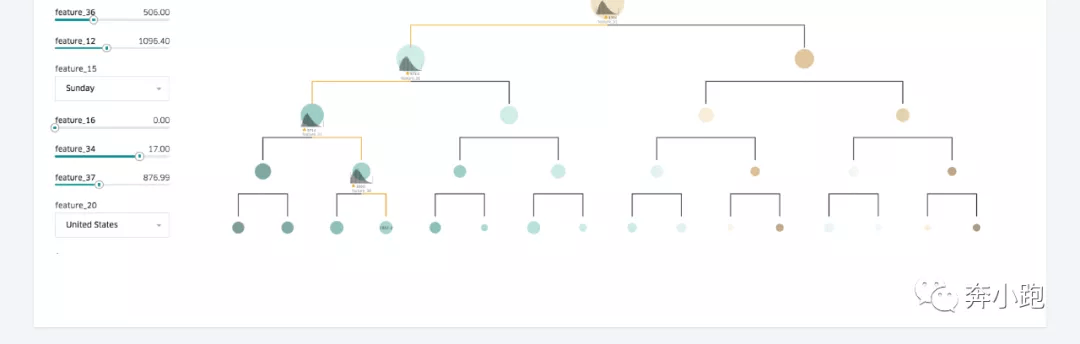
3.3.2 可视化决策树
可视化工具可以帮助建模者更好地理解模型的行为原理,并在建模者需要时帮助其进行调试。
举例:决策树模型。用户可以输入一个特征值,可视化组件将会遍历整个决策树的触发路径、每个树的预测、整个模型的预测,将数据展示成类似下图的样子:
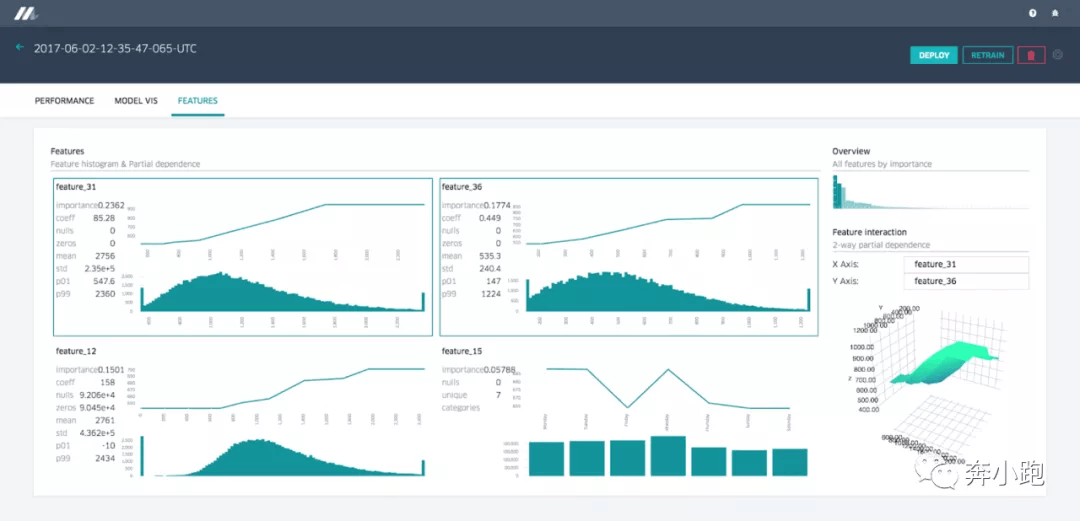
3.3.3 特征报告
Michelangelo 提供了特征报告,在报告中使用局部依赖图以及混合直方图展示了各个特征对于模型的重要性、不同特征间的相关性。选中两个特征可以让用户看到它们之间相互的局部依赖图表:
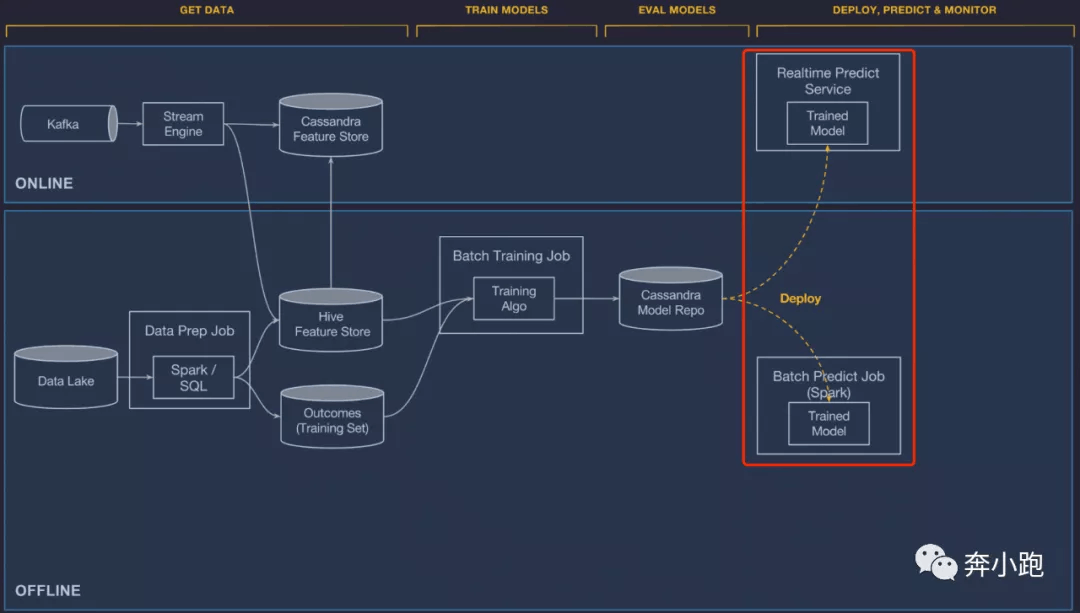
3.4 部署模型
Michelangelo 支持使用 UI 或 API 端对端管理模型的部署。三种部署方式:
- 离线部署。 模型将部署于离线容器中,使用 Spark 作业,根据需求或计划任务进行批量预测。
- 在线部署。 模型将部署于在线预测服务集群(集群通常为使用负载均衡部署的数百台机器),客户端可以通过网络 RPC 调用发起单个或批量的预测请求。
- 部署为库。 工程师们希望能在服务容器中运行模型。可以将其整合为一个库,也可以通过 Java API 进行调用。
3.5 预测结果
- 模型为在线模型,预测结果将通过网络传回给客户端。
- 模型为离线模型,预测结果将被写回 Hive,之后可以通过下游的批处理作业或者直接使用 SQL 查询传递给用户。

Michelangelo 支持同时向服务容器部署多个模型,可以用以对模型进行 A/B 测试。使用客户端服务中的 Uber 实验框架将部分流量导至各个模型,再对性能指标进行评估。
3.6 预测监控
Michelangelo 系统会自动记录并将部分预测结果加入到数据 pipeline 的标签中去,有了这些信息,就能得到持续的、实时的模型精确度指标。
举例:回归模型,会将 R^2/决定系数、均方根对数误差(RMSLE)、均方根误差(RMSE)以及平均绝对值误差发布至 Uber 的实时监控系统中,用户可以分析指标与时间关系的图标,并设置阈值告警。
四 Michelangelo PyML 加速模型开发
PyML 是 Michelangelo 的扩展,加快模型的迭代效率,允许算法工程师调用任意 Python 库实现模型,快速上线模型进行评估。

PyML 架构:
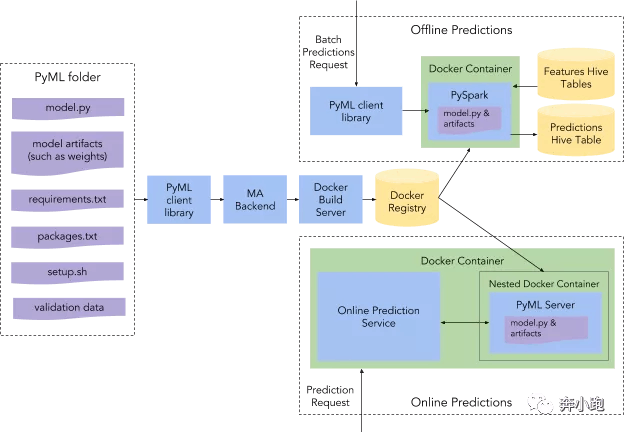
- 模型和依赖项被上传到米开朗基罗 (MA) 的后端并由其进行版本控制
- 构建一个 Docker 镜像,该镜像可以部署为 Docker 容器
- 进行在线预测或用于运行大规模离线预测。
4.1 使用PyML例子
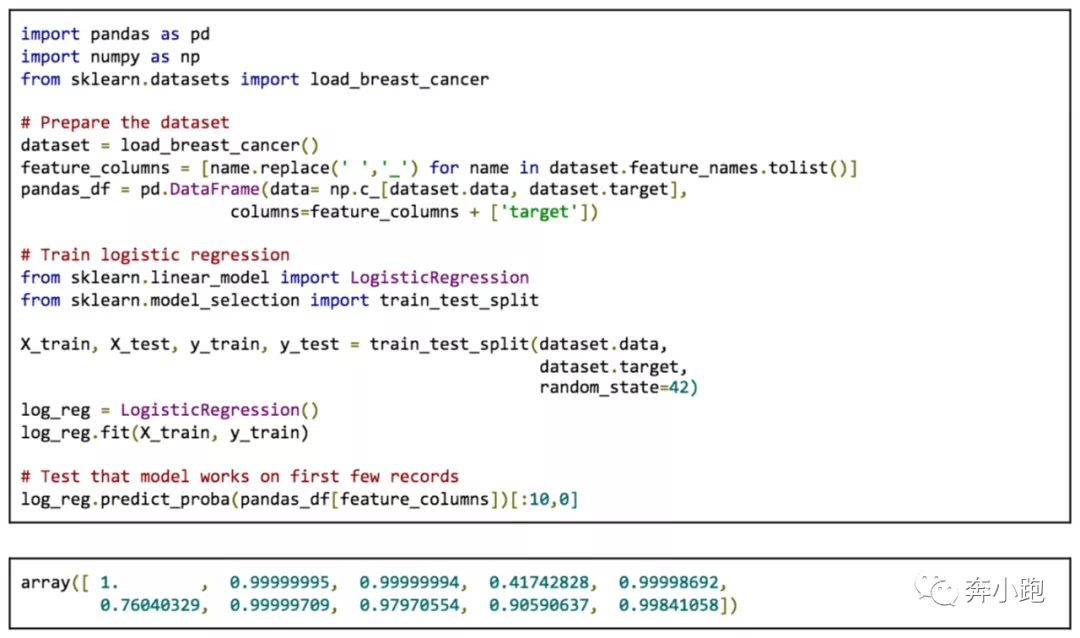
4.1.1 训练模型
训练模型独立于 PyML。算法工程师可以在 Jupyter Notebook 中使用任意 Python 库进行特征和标签的获取,模型的定义,并进行训练。
4.1.2 保存模型

4.1.3 调整模型为 PyML 契约定义

4.1.4 声明库依赖

4.1.5 载入模型验证有效

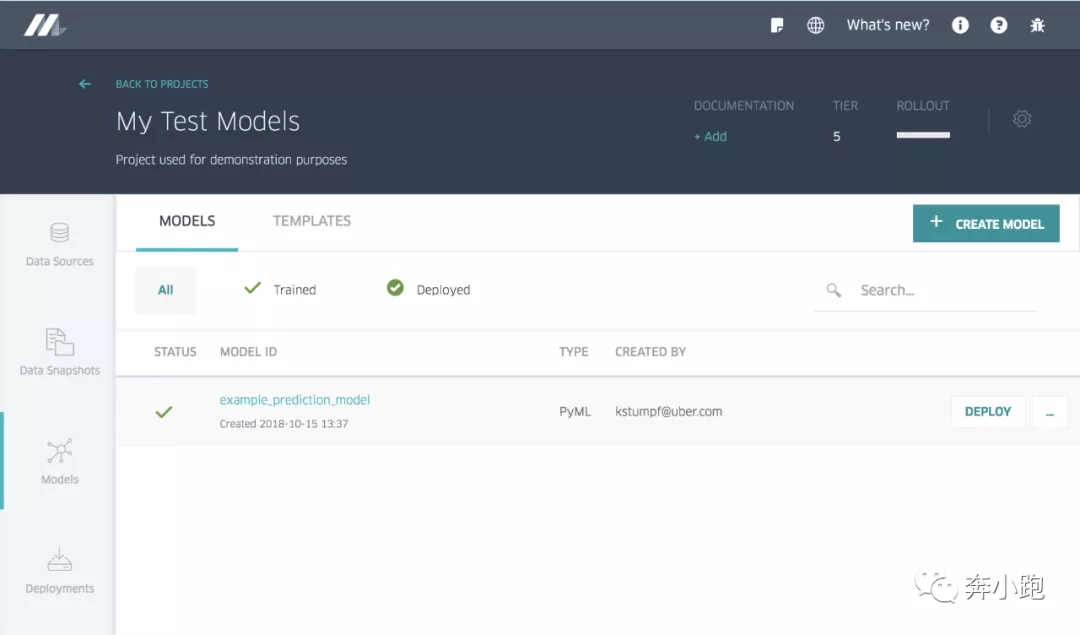
4.1.6 打包模型上传仓库

打包上传后的模型在 Michelangelo 中可以进行版本控制和管理。在 Michelangelo 的 UI 中使用如下图示:
4.1.7 部署模型并预测
部署模型:

在线预测:

离线预测:

五 小结
Uber没开源Michelangelo,它发布的说明文档,记录了关于实现可扩展机器学习流水线的设计思路与最佳实践。对构建和完善我们自己的机器学习平台是个参考。
- 平台的工作流程参考
- 集中式特征存储、模型性能报告、低延迟实时预测服务、深度学习工作流
- 工具化、可视化操作