这是我以前在自然语言课程中的一个小作业,之前发在我的公众号“奔小跑”里,现在再把它记录在自己的博客(benxiaopao.com)里。内容主要介绍了文本相似度、余弦定理、特征权重计算方法TF-IDF、基于余弦定理计算相似度方法评价、代码实现思路和实验效果与演示。
一. 文本相似度
文本相似度在不同的领域中都有广泛的应用。例如:在机器翻译系统中,一个词语一般会用几个意思相同或者相近的词语进行解释,这就侧重于考量词语之间的相似度;在FAQ自动问答系统中,用户查询的问句需要能迅速的在数据库找到匹配问句的答案,这考量的是句子与句子之间的相似度,其中还要包含一定的语义相似度;在文本查重、版权维护与副窃检测系统中,相似度是以段落与段落之间的相似度来衡量的;在信息检索中为了使检索结果更迅速、准确,需要对数据中的文本集合进行分类、聚类、排序等操作,这就需要分析计算文本与文本之间的相似程度。
相似度计算的应用意义重大。例如:存储文本时,相似度计算可以缩短文本信息占用的空间;相似度计算在维护版权方面,通过检测两个文本的相似程度可以判断是否存在剽窃现象,有助于维护知识产权,尊重他人成果,提高学术研究的独创性。
二. 余弦定理
我们在中学的时候都学习过余弦知识。余弦定理是描述三角形中三边长度与一个角的余弦值关系的数学定理,是勾股定理在一般三角形情形下的推广,勾股定理是余弦定理的特例。余弦定理是揭示三角形边角关系的重要定理,直接运用它可解决一类已知三角形两边及夹角求第三边或者是已知三个边求三角的问题,若对余弦定理加以变形并适当移于其它知识,则使用起来更为方便、灵活。
数学中常用余弦定理来计算两条边的夹角,NLP中可以用余弦定理来计算文本相似度。计算两个向量的余弦定理,求得的夹角 θ 越小,说明两个向量越接近,计算公式如下:
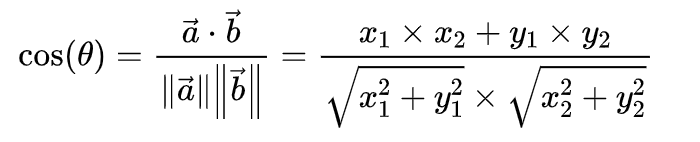
这里向量a与向量b表示如下:
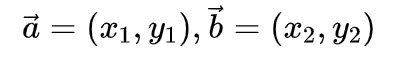
上面的向量是按二维的形式表达的,但向量一般是多维的情况,因此需要对余弦定理进行泛化表示,使其能计算多维空间的距离,扩展公式如下:
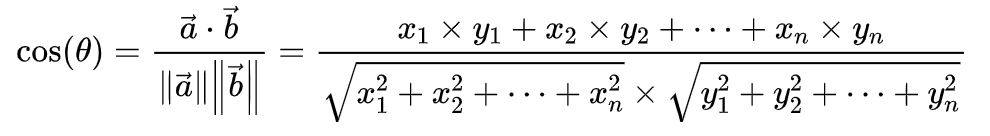
这里向量a与向量b表示如下:
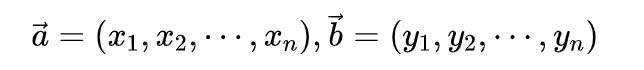
文本的余弦定理相似度计算方法采用以字作为向量或者以词作为向量,然后计算每个字或者词出现的次数作为向量的分量,即通过计算两个向量的夹角余弦值来计算它们的相似度。
三. 特征权重计算方法TF-IDF
TF(term frequency):词频,某一个给定的词语在该文件中出现的频率,表示一个词语与该文章的相关性。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。
IDF(inverse document frequency):逆向文件词频,表示一个词语出现的普遍程度。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
TF-IDF的核心思想是:在一篇文章中,某个词语的重要性与该词语在这篇文章中出现的次数成正相关,同时与整个语料库中出现该词语的文章数成负相关。
一篇文章中某个词语的重要程度,可以标记为词频和逆向文件词频的乘积,即tfidf=tf∗idf。通过计算出文档中每个词的TF-IDF值,然后结合余弦定理相似度计算方法就可以计算两个文档的相似度。
四. 基于余弦定理计算相似度方法评价
通过余弦定理计算两篇文本相似度的方法实现相对容易,但是忽略了文本中词项的语义信息,主要依靠字或词出现的次数来衡量两篇文本的相似度,准确性比基于关键词匹配的传统方法准确性要高,比起深度学习的相似度方法,准确性要低,如基于用户点击数据的深度学习语义匹配模型DSSM,基于卷积神经网络的ConvNet,以及目前state-of-art的Siamese LSTM等方法。
五. 代码实现
整体实现思路是:通过Python图形开发界面tkinter做了简单的界面功能,有两个输入文本框项,便于用户输入需要比较相似度的两篇文本内容,界面中还有一个“计算文本相似度”的按钮,用户点击后,程序会将两个文本内容先通过第三方中文分词库jieba进行分词,再将两篇文档内容通过TF-IDF的特征权重计算方法分别对文档进行向量化表示,然后运用余弦定理计算出两个文档向量的余弦相似度,最后把该余弦相似度结果显示在界面上。完整代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import jieba
from tkinter import *
from tkinter.ttk import *
from tkinter.messagebox import *
class ApplicationUI(Frame):
""" 这个类仅实现界面生成功能 """
def __init__(self, master=None, width=800, height=600):
Frame.__init__(self, master)
self.master.title('NLP作业')
# 居中显示
ws = self.master.winfo_screenwidth()
hs = self.master.winfo_screenheight()
x = int((ws / 2) - (width / 2))
y = int((hs / 2) - (height / 2))
self.master.geometry('{}x{}+{}+{}'.format(width, height, x, y))
self.create_widgets()
def create_widgets(self):
self.top = self.winfo_toplevel()
self.style = Style()
self.notebook = Notebook(self.top)
self.notebook.place(relx=0.02, rely=0.02, relwidth=0.96, relheight=0.96)
self.notebook_tab1 = Frame(self.notebook)
self.notebook_tab1_lbl1 = Label(self.notebook_tab1, text='文本1:')
self.notebook_tab1_lbl1.grid(row=0, column=0, padx=(50, 10), pady=50)
self.notebook_tab1_text1 = Text(self.notebook_tab1, height=10)
self.notebook_tab1_text1.grid(row=0, column=1, pady=(50,0))
self.notebook_tab1_lbl2 = Label(self.notebook_tab1, text='文本2:')
self.notebook_tab1_lbl2.grid(row=1, column=0, padx=(50, 10), pady=50)
self.notebook_tab1_text2 = Text(self.notebook_tab1, height=10)
self.notebook_tab1_text2.grid(row=1, column=1, pady=(15,0))
self.notebook_tab1_btn = Button(self.notebook_tab1, text="计算文本相似度", command=self.calculate_similarity)
self.notebook_tab1_btn.grid(row=2, column=1, columnspan=2, pady=(50,0))
self.notebook_tab1_lbl4 = Label(self.notebook_tab1, text='')
self.notebook_tab1_lbl4.grid(row=3, column=1, columnspan=2)
self.notebook.add(self.notebook_tab1, text='文本相似度计算')
class Application(ApplicationUI):
""" 这个类实现具体的事件处理回调函数,子类 """
def __init__(self, master=None):
ApplicationUI.__init__(self, master)
def calculate_similarity(self):
doc1 = self.notebook_tab1_text1.get(0.0,END)
doc2 = self.notebook_tab1_text2.get(0.0,END)
doc1 = doc1.strip()
doc2 = doc2.strip()
print(doc1)
print(doc2)
if len(doc1)==0:
showwarning('提示', '请输入文本1')
return
if len(doc2)==0:
showwarning('提示', '请输入文本2')
return
sim = Sim()
similarity_result = sim.similarity(doc1, doc2)
print(similarity_result)
self.notebook_tab1_lbl4["text"] = "计算结果:" + str(similarity_result)
class Sim(object):
def __init__(self, kernel='tfidf'):
self.word2idx = {}
self.kernel = kernel
def tokenizer(self, sent):
return jieba.lcut(sent)
def calc_bow(self, docs):
'''
计算词袋向量
:param docs:
:return:
'''
bow = np.zeros([len(docs), len(self.word2idx)])
for docidx, words in enumerate(docs):
for word in words:
if word in self.word2idx:
bow[docidx, self.word2idx[word]] += 1
return bow
def calc_tfidf(self, docs):
'''
计算tfidf
:param docs:
:return:
'''
tf = self.calc_bow(docs)
df = np.ones([1, len(self.word2idx)])
for docidx, words in enumerate(docs):
tf[docidx] /= np.max(tf[docidx])
for word in words:
if word in self.word2idx:
df[0, self.word2idx[word]] += 1
idf = np.log(len(docs)) - np.log(df)
tfidf = tf * idf
return tfidf
def cos(self, vec1, vec2):
'''
计算余弦相似度
:param vec1:
:param vec2:
:return:
'''
cos = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
try:
cos = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
except:
cos = None
return cos
def similarity(self, doc1, doc2):
'''
计算文本相似度
:param doc1:
:param doc2:
:return:
'''
words1 = self.tokenizer(doc1)
words2 = self.tokenizer(doc2)
# 求并集
words = set(words1) | set(words2)
self.word2idx = dict(zip(words, range(len(words))))
if self.kernel == 'tfidf':
feature = self.calc_tfidf
else:
feature = self.calc_bow
vec = feature([words1, words2])
vec1 = vec[0]
vec2 = vec[1]
return self.cos(vec1, vec2)
if __name__ == '__main__':
top = Tk()
Application(top).mainloop()
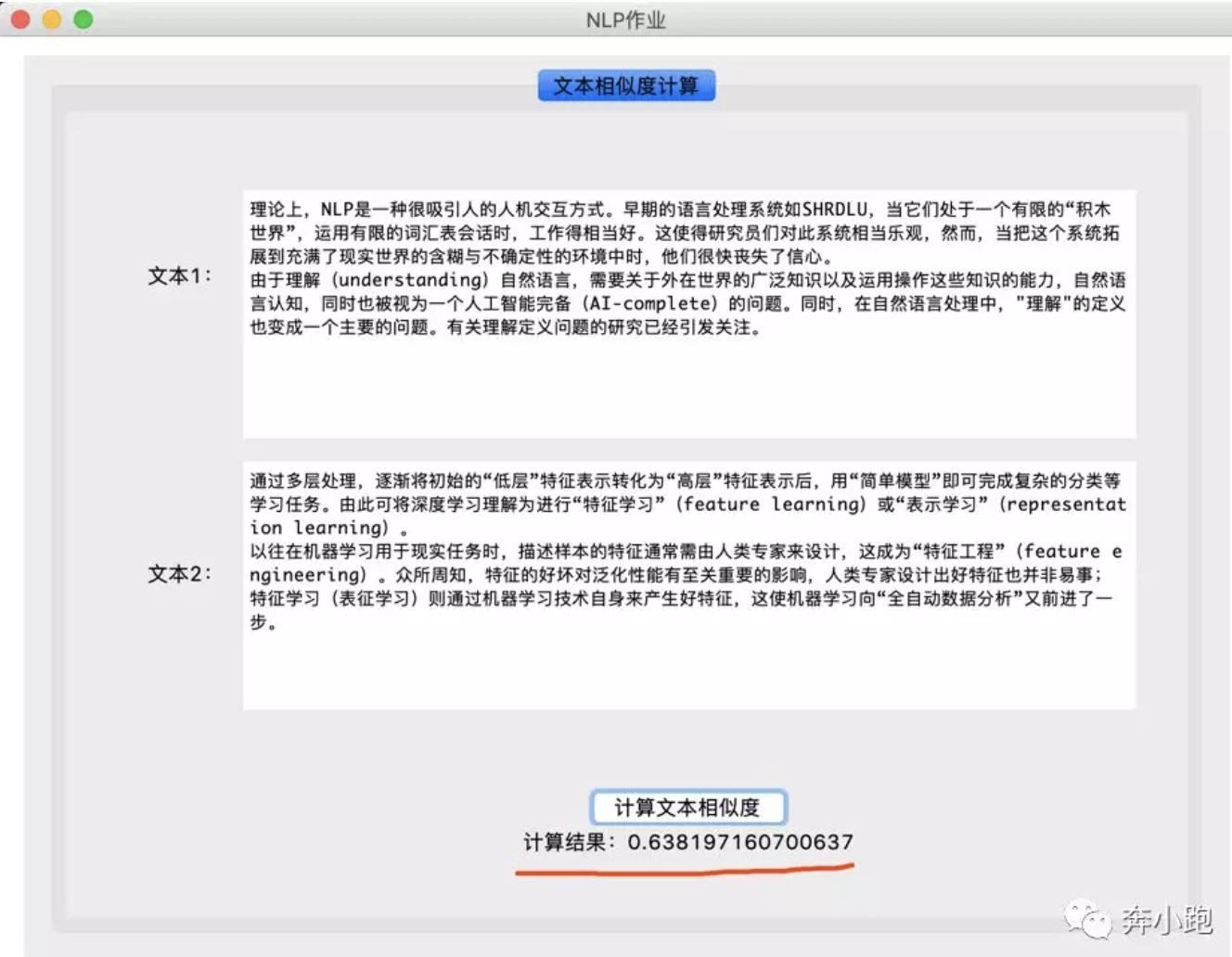
六. 运行效果
运行后的界面截图:
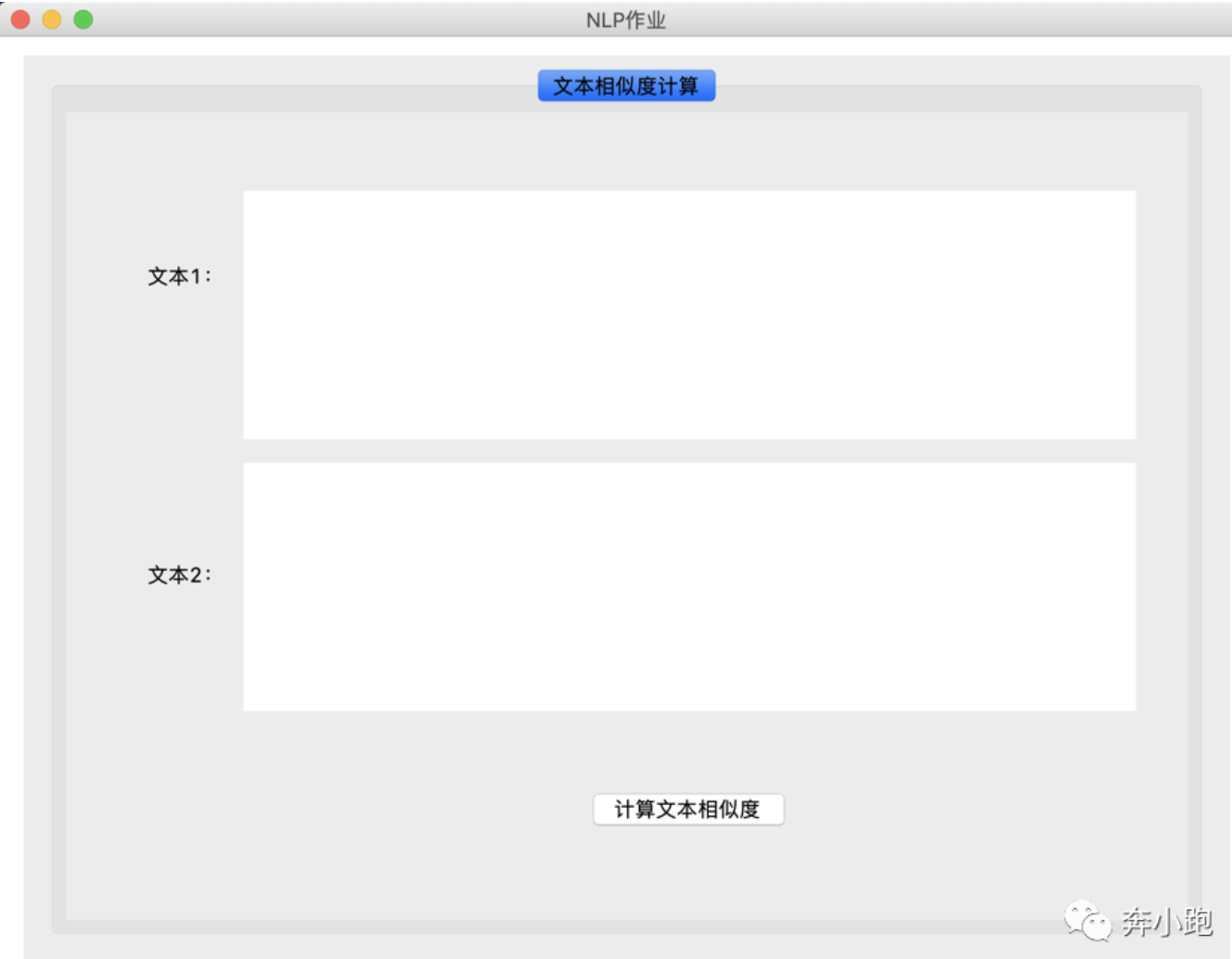
在文本1和文本2对应的输入框中分别输入文本内容,截图如下:

点击“计算文本相似度”按钮,程序就会通过余弦定理计算两段文本的相似度,计算后结果截图如下: